La indexación de la página web o lo que comúmente se ha llamado alta en buscadores es sin duda un paso fundamental para todos los que comienzan con su página web o blog. Tenemos que facilitar que otros usuarios encuentren nuestro sitio web y para ello se lo tenemos que poner fácil a Google.
Cuando tenemos nuestra página web o blog terminado lo que todos queremos -o deberíamos querer- es que google nos indexe pero ¿cómo sabemos que nuestro sitio cumple con estas premisas?
En este artículo quiero darte una guía básica para facilitar la indexación de tu página web y de su contenido.
Análisis de indexabilidad
En este primer paso lo que tenemos que hacer es asegurarnos de que nuestro sitio está en condiciones de ser encontrado por los motores de búsqueda.
Para ello tenemos que tener claro que tanto el código que compone nuestra web como la navegabilidad entre su contenido, debe de facilitar que las arañas de los buscadores pueden rastrear y acceder a todo el contenido que queremos mostrar de nuestra web.
¿Qué es un crawler o araña?
Llamamos araña o crawler a un programa que rastrea y navega por nuestro contenido web. Para muchos las arañas son motores de búsqueda, pero realmente su aplicación puede ser muy amplia. Por ejemplo:
- Rastrear todos los usuarios de una plataforma copiar sus emails y luego usarlos para mandarles publicidad.
- Automatizar la lectura de los competidores e informarte de los cambios que se realizan en su web.
Hay ciertas etiquetas que impiden que estas arañas accedan a nuestro contenido por eso es muy importante que no estemos impidiendo su acceso. Estas etiquetas se activan por código y a no ser que las hayamos puesto voluntariamente, no deberían estar.
Hay plugins como YOAST SEO by Wordpress o ALL IN ONE SEO que te facilita el trabajo con estas etiquetas
Para ver estas etiquetas hay que acceder al código de la página, los exploradores (Chrome, Firefox, Safari...) actuales facilitan esta tarea y solo tienes que pinchar en el botón derecho cuando estés encima de la web y seleccionar "ver código fuente de la página".
Este es un ejemplo del código fuente de mi web.
![]()
Como puedes ver la etiqueta <meta name="robots"> es la encargada de dar acceso o impedirlo a las diferentes arañas. Sin profundizar en el tema, tenéis que saber que no solo Google tiene arañas, sino que hay miles de arañas que rastrean el World Wide Web (algunas no traen buenas intenciones).
Podemos bloquear el acceso a una araña individualmente si conocemos su nombre. El crawler (para que nos vayamos quedando con la palabra inglesa) de Google se llama Googlebot.
Para indicar a cualquier motor que no indexe mi web solo tendría que poner el indicador "noindex". En estos momentos yo tengo indicado "noodp" este es un valor que impide que se utilice la descripción alternativa de ODP/DMOZ.
Hay otro valor muy importante para que Googlebot pueda acceder a todo nuestro contenido y es el indicador Follow o Nofollow, este viene a decirle a la araña que los enlaces indicados con este valor no los siga. Es decir, esto impediría al Crawler avanzar en la lectura del contenido .
*El valor Follow y Nofollow es muy utlizado en el enlazado para el SEO, pero no lo explicaré en este artículo.
Cómo saber si mi página web está indexada en Google
Si hemos seguido y creado nuestra web correctamente al cabo de un tiempo nuestra página debería ser indexada automáticamente por Google y los demás buscadores sin tener que hacer nada.
Pero en ocasiones esto no ocurre o simplemente queremos acelerar este proceso.
Cuando comienzo con un proyecto SEO, lo primero que suelo hacer es un estudio de indexación.
Indexabilidad. Comenzando.
En este artículo no vamos a profundizar en otros temas referentes con la indexación como pueden ser contenido duplicado, contenido oculto, problemas de accesibilidad, etc... Prefiero dejarlo para otros artículos y poder ofreceros herramientas para facilitar esas tareas.
El primer paso que realizo es comprobar el estado de la web y eso lo podemos hacer introduciendo en la barra del buscador el operador SITE: seguido del nombre de nuestra web. Ejemplo:
site:redframe.es
Al introducir este operador, Google nos devolverá todos los resultados indexados bajo ese dominio. Si no devuelve nada, nuestra web no está indexada.
Hay un termino que se utiliza para indicar la relación entre nuestras páginas indexadas y las páginas reales, esta relación debería acercarse a 100% y la llamaremos SATURACIÓN.
Para saber nuestras páginas creadas debemos crear un sitemap. Más abajo os diré cómo crearlo.
Después de este punto recomiendo dar de alta nuestro proyecto (verificación) en la herramienta que nos facilita Google.
Search Console
Search Console, antiguamente llamada Google Webmaster Tools, es una herramienta creada por Google para los webmasters. En ella nos da multitud de datos para que vayamos mejorando la web de cara a los buscadores -y usuarios-.
Para comenzar solo debemos crearnos una cuenta de Gmail (si ya tienes una puedes utilizar para la herramienta) y añadir nuestra primera propiedad.
Una vez añadida, debemos verificarla. La herramienta nos da distintas opciones para realizar la verificación. Con esta acción le decimos que somos los propietarios o tenemos el acceso para trabajar con una web.
Una web puede estar verificada por dos personas distintas.
La opción más sencilla es la de subir el archivo que nos facilitan a nuestra raíz desde el ftp o panel de nuestro proveedor de hosting.
Siempre hay que añadir las dos opciones de nuestra web con o sin www. Ya que hay que decirle al buscador cuál es nuestro dominio, en el próximo artículo hablaremos más detenidamente de esto, ya que estaríamos duplicando todo nuestro contenido.
Hay que elegir entre:
www.nuestraweb.com ó nuestraweb.com
Crear sitemap de nuestra página web
Cuando creamos un sitemap lo que queremos es ponérselo fácil a los rastreadores. Actualmente los rastreadores son tan "hábiles" que aunque no añadamos un sitemap debería de poder rastrear nuestra web, pero nunca está de más hacer un sitemap.
Los archivos de sitemap ofrecen a los buscadores una lista con todas las páginas que deben indexar.
Herramientas para crear sitemap hay muchas. Las gratuitas están limitadas a un número de páginas, pero para proyectos normales debería bastarnos.
Esta es una de las opciones gratuitas que podéis utilizar. Personalmente prefiero crear mis sitemaps con Screaming Frog. Herramienta que animo a utilizar si os vais a dedicar al mundo del SEO.
El sitemap debéis subirlo, al igual que sucedía con el archivo de verificación de propiedad, a la raíz del hosting donde tengáis vuestra página web.
Posteriormente a través de nuevo de Search Console, entráis en la web a administrar y os vaís a la parte izquierda del menu.
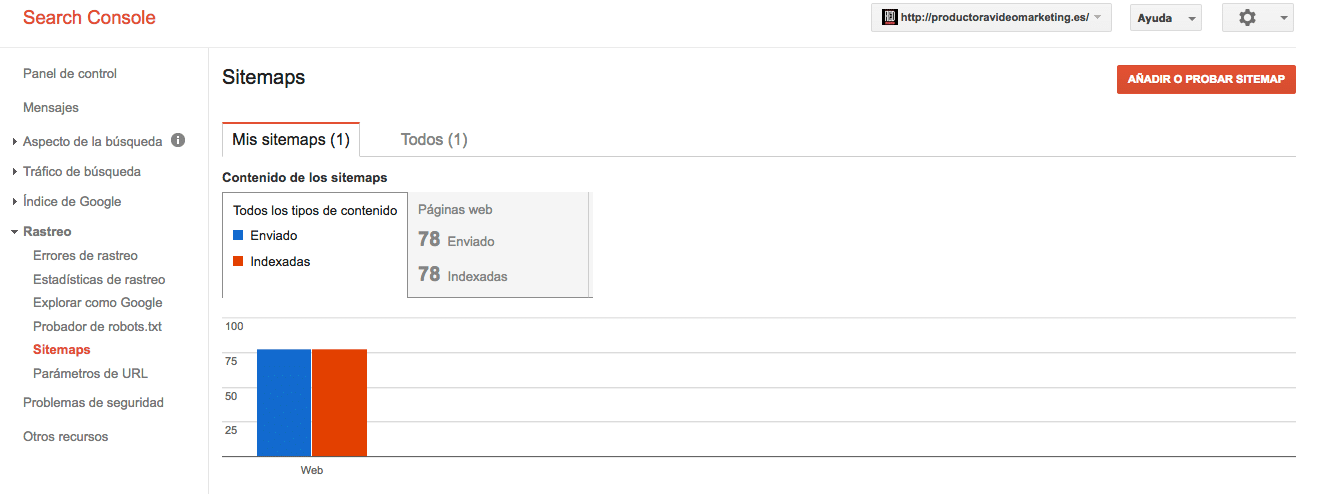
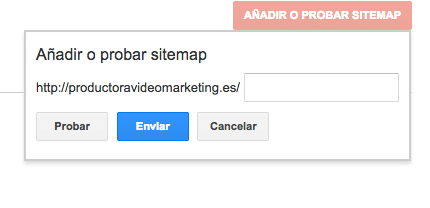
Luego solo tenéis que poner la dirección donde se encuentra el sitemap. Siempre en la raíz de vuestra página web, normalmente los proveedores te dicen dónde está la raíz de tu página web, suele ser un directorio llamada public-html, pero depende del host y el proveedor.
En mi caso pondría en la casilla que me facilitan "sitemap.xml" y lo enviaría.
Crear archivo Robots.txt
Este debería ser un paso sencillo y rápido. Lo que yo recomiendo es crear un archivo robots simple, al menos en una primera instancia.
Una forma muy sencilla es abrir un editor de textos y leer el robots.txt de una web similar a la nuestra, si sabemos el gestor de contenidos que utilizar mucho mejor, es decir si es wordpress ir a una wordpress.
Como detalle indicar que hay CMS (gestores de contenido) que crean estos archivos.
Tanto los archivos sitemap.xml y robots.txt son archivos de lectura, y deberíamos poder leerlos de todas las webs. Podéis hacer la prueba, solo tenéis que conocer cómo se llama el archivo, no siempre se llama sitemap.
Probando el Robots.txt de marca.com
marca.com/robots.txt
User-agent: * Disallow: /s/ Disallow: /corporativo/aviso-legal.html Disallow: /corporativo/contacto.html Disallow: /corporativo/ayuda.html Disallow: /multimedia/en-tu-movil/listado/index.html Disallow: /social/ Disallow: /edicion/ Disallow: /eltiempo/ Disallow: /deporte/futbol/primera-division/2010-2011/panel-de-fichajes/* Disallow: /eventos/marcador/futbol/2013_14/* Disallow: /eventos/marcador/futbol/2012_13/* Disallow: /eventos/marcador/futbol/2011_12/* Disallow: /encuentros/roberto-palomar/2016/03/29/*
En el archivo de robots.txt de marca vemos como el indicador Disallow le indicar al robots que no siga los siguientes directorios.
El indicador "user-agent: * " está habilitando todos los crawlers.
Si miráis mi archivo robots.txt podéis comprobar que yo tengo bloqueados otros crawlers diferentes, normalmente son de spam.
https://redframe.es/robots.txt
Una vez finalizado este paso, iría a la parte para mandar mi url al índice de google.
Indicar en Search Console que mande mi página al índice de Google
Vamos al menú de nuestra izquierda y seleccionamos la opción de "Explorar como Google".

Una vez allí vamos a indicar que obtenga y procese nuestra url para posteriormente indicar que la mande al índice de google.
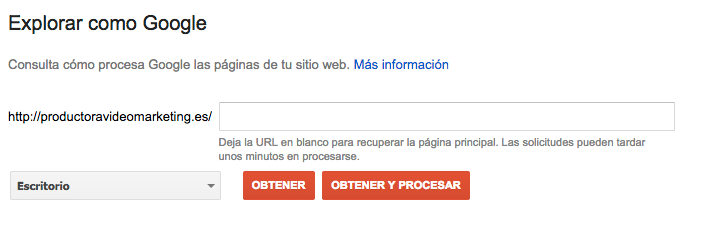
Esta operación suele ser rápida, en un par de días nuestra web debería estar indexada.